









How to Prepare For and PASS Data Architecture and Management Designer Exam

This post introduces a series of articles exclusively devoted to the Technical Architect (TA) Exam path. There have been some unclarities about a number and a kind of modules that will be obligatory prior to taking the final TA exam in person in front of the board of examiners. We have finally confirmed a clear picture of the path that is leading to the highest ranks in the Salesforce world.
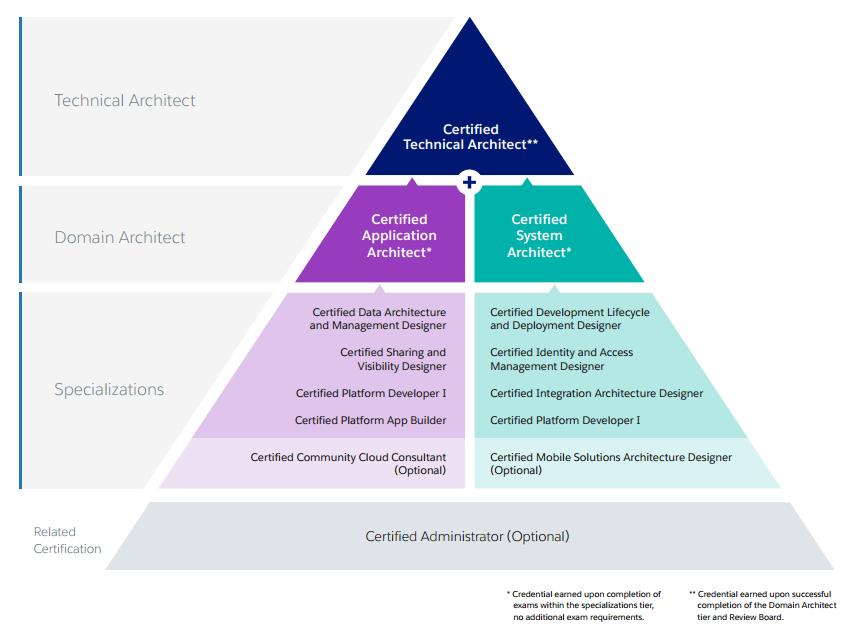
There are 9 modules that are divided into 2 domain specializations: Application Architect and System Architect. However, 2 of them (Community Cloud Consultant and Mobile Solutions Architecture Designer) seem to be optional so in reality a candidate has to pass 7 modules to be able to take the final exam. Some of the modules have been present in the market for some time. These modules are App Builder exam and Platform Developer I (requisitive in both Domain Architect paths). In this blog post series I would like to talk a little bit more about the remaining modules, starting from Data Architecture and Management Designer.
Let’s start with some overview of target audience:
The Salesforce Certified Data Architecture and Management Designer credential is intended for the designer who assesses the architecture environment and requirements and develops sound, scalable, and performance solutions on the Force.com platform as it pertains to enterprise data management. The candidate understands information architecture frameworks covering major building blocks such as data sourcing, integration/movement, persistence, master data management, metadata management and semantic reconciliation, data governance, security, and delivery.
I’ve just passed the exam and have to admit that somehow it seems easier than other platform-specific exams like Sales Cloud or Service Cloud. Most of the questions are common sense ones dealing with engineering challenges rather than platform features.
Large Data Volumes (LDV)
There are a number of questions concerning that issue. Basically when you hit 2 million records threshold we can start talking about LDV. There are some areas that may be affected by such an amount of records:
- Reports
- Search
- Listviews
- SOQL
To have a better overview of the topic I strongly recommend going through Salesforce’s Best Practices for Deployments with Large Data Volumes ebook.
There is a nice chapter devoted to the database architecture. It’s quite eye opening in terms of how data is stored, searched and deleted in Salesforce:
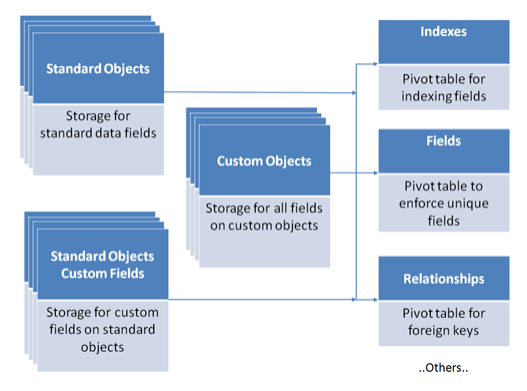
There are some key challenges connected with LDV:
- Data Skew – each record shouldn’t have more than 10k children; data should be even distributed
- Sharing Calculation Time – one can defer sharing calculation when loading big chunks of data into system
- Upsert Performance – better to seperately insert and then update records; upsert is quite expensive operation
- Report Timeouts
- Apply selective report filtering
- Non-Selective Queries (Query Optimization)
- Make query more selective: reduce the number of objects and fields used in a query
- Custom Indexes
- Avoid NULL values (these are not indexed)
- PK Chunking Mechanisms
- Data Reduction Considerations:
- Archiving – consider off-platform archiving solutions
- Data Warehouse – consider a data warehouse for analytics
- Mashups – real-time data loading and integration at the UI level (using some VF page)
Skinny Tables
Skinny tables are quite an interesting concept that I was not aware of before.
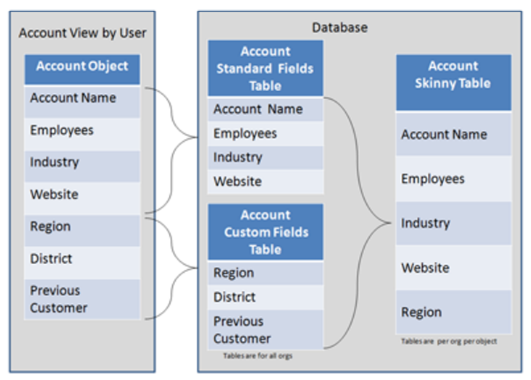
Salesforce creates skinny tables to contain frequently used fields and to avoid joins, and it keeps the skinny tables in sync with their source tables when the source tables are modified. To enable skinny tables, contact Salesforce Customer Support. For each object table, Salesforce maintains other, separate tables at the database level for standard and custom fields. This separation ordinarily necessitates a join when a query contains both kinds of fields. A skinny table contains both kinds of fields and does not include soft-deleted records. This table shows an Account view, a corresponding database table, and a skinny table that would speed up Account queries.
Indexes
Indexes Salesforce supports custom indexes to speed up queries, and you can create custom indexes by contacting Salesforce Customer Support.
The platform automatically maintains indexes on the following fields for most objects.
- RecordTypeId
- Division
- CreatedDate
- Systemmodstamp (LastModifiedDate)
- Name
- Email (for contacts and leads)
- Foreign key relationships (lookups and master-detail)
- The unique Salesforce record ID, which is the primary key for each object
Salesforce also supports custom indexes on custom fields, with the exception of:
- multi-select picklists
- text area (long)
- text area (rich)
- non-deterministic formula fields (like ones using TODAY or NOW)
- encrypted text fields.
External IDs cause an index to be created on that field, which is then considered by the Force.com query optimizer. External IDs can be created on only the following fields:
- Auto Number
- Number
- Text
Data Loading
You have to know ways to integrate Salesforce with data from external systems:
- ETL Tools
- SFDC Data Import Wizard
- Data Loader
- Outbound Messages
- SOAP and REST API
This is crucial here to know a little bit about Bulk API.
Bulk API is based on REST principles and is optimized for loading or deleting large sets of data. You can use it to query, insert, update, upsert, or delete many records asynchronously by submitting batches. Salesforce processes batches in the background.
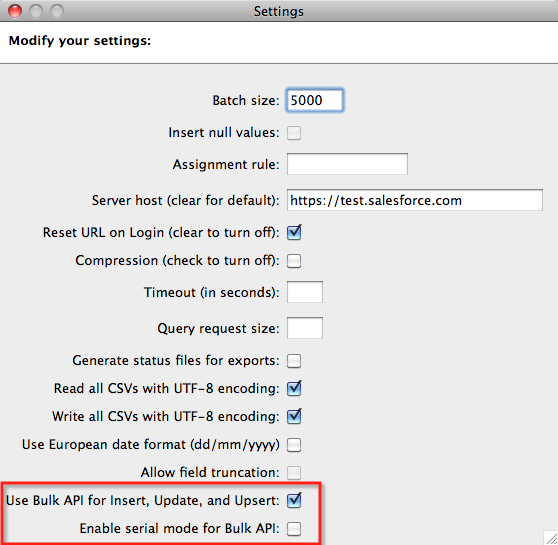
Interesting fact is that Data Loader can also utilize Bulk API. You just have to explicitly switch it on in the settings:
Source: https://developer.salesforce.com/page/Loading_Large_Data_Sets_with_the_Force.com_Bulk_API
Behind the scenes Bulk API uploads the data into temporary tables then executes processing of the data (actual load into target objects) using parallel asynchronous processes:
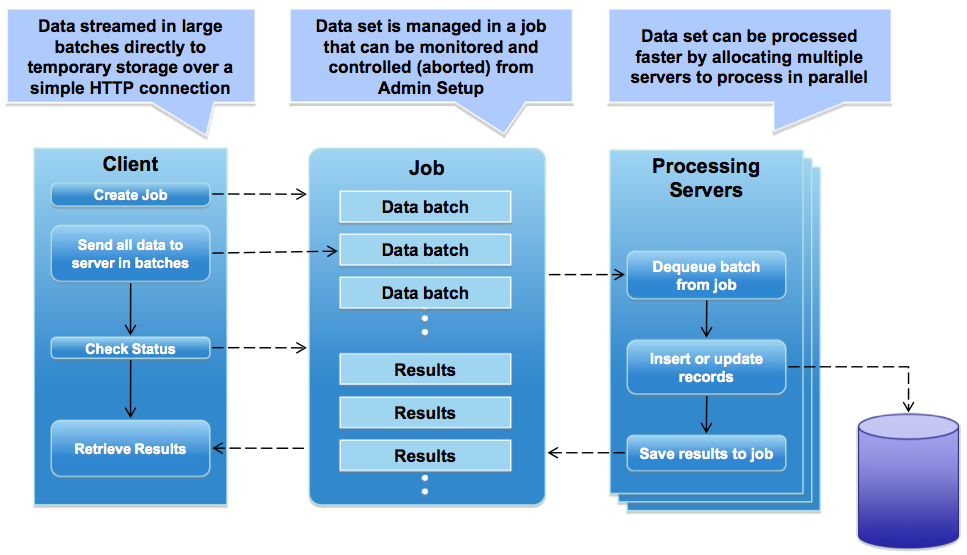
Source: https://developer.salesforce.com/page/Loading_Large_Data_Sets_with_the_Force.com_Bulk_API
As mentioned in the LDV section you have to keep in mind few things when uploading data:
- Disable triggers and workflows
- Defer calculation of sharing rules
- Insert + update is faster than upsert
- Group and sequence data to avoid parent record locking
- Tune the batch size (HTTP keepalives, GZIP compression)
Data Quality
There is some nice overview from Salesforce – 6 steps toward top data quality:
- Use exception reports and data-quality dashboards to remind users when their Accounts and Contacts are incorrect or incomplete. Scheduling a Dashboard Refresh and sending that information to managers is a great way to encourage compliance
- When designing your integration, evaluate your business applications to determine which one will serve as your system of record (or “master”) for the synchronization process. The system of record can be a different system for different business processes
- Use Workflow, Validation Rules, and Force.com code (Apex) to enforce critical business processes
- Use in-built Salesforce Duplicate Rules and Matching Rules mechanisms
You can find more info about Data Management Plan on Trailhead.
Other imporant terms:
- Data Governance – refers to the overall management of the availability, usability, integrity, and security of the data employed in an enterprise. A sound data governance program includes a governing body or council, a defined set of procedures, and a plan to execute those procedures
- Data Stewardship – management and oversight of an organization’s data assets to help provide business users with high-quality data that is easily accessible in a consistent manner
Good luck folks!

There was a question along the lines of:
A customer has an ERP system, an ODM system, and Salesforce CRM system. What should an architect consider when choosing whether or not to use MDM (Select 2)
Legacy CRM Transfer
On Premise or cloud system
The number of systems to integrate
The tables have different source of truth
I struggled with this question because none of these really matter when choosing MDM do they? It doesn’t matter if its a cloud system or not you could still use MDM. There isn’t a maximum number of systems in an mdm right? It doesn’t matter if there is a legacy system, you can still use MDM. And it doesn’t matter if there are multiple source of truth tables you could still use MDM. Maybe the question means what to consider when choosing an implementation style of MDM? What are your thoughts?
I would select “The tables have different source of truth” and “The number of systems to integrate”.
Thank you! This helped me pass my exam today!
Glad to hear that 🙂
Hello,
I’m preparing for my exam and I’m having trouble with this practice question:
Universal Containers keeps its Account data in Salesforce and its Invoice data in a third -party ERP system. They have connected the Invoice data through a Salesforce external object. They want data from both Accounts and Invoices visible in one report in one place. What two approaches should an architect suggest for achieving this solution? Choose 2 answers
A. Create a report in an external system combining Salesforce Account data and Invoice data from the ERP.
B. Create a report combining data from the Account standard object and the Invoices external object.
C. Create a Visualforce page combining Salesforce Account data and Invoice external object data.
D. Create a separate Salesforce report for Accounts and Invoices and combine them in a dashboard.
To me, A B & C seem possible. Can you help me, it says the answer is A & C
But B should be true as well: (https://releasenotes.docs.salesforce.com/en-us/winter17/release-notes/rn_rd_external_object_reports.htm)
What do you think?
Hmm, looks like a legit way to create report as well. Maybe that is some old question, it seems that this feature was introduced in Winter 17. Where did you find that – some dumps?
I found like 5 sample questions and that was 1 of them. I figured it was an old question.
HI Maciej,
Please provide any suggestions on how to prepare for Data architecture and management designer certification.
Regards,
Daniel
Can you validate my response. I am trying to take the test 2nd time .
2. UC is trying to switch from legacy CRM to salesforce and wants to keep legacy CRM and salesforce in place till all the functionality is deployed in salesforce. The want to keep data in synch b/w Salesforce, legacy CRM and SAP. What is the recommendation
a. Do not integrate legacy CRM to Salesforce, but integrate salesforce to SAP
b. Integrate legacy CRM to salesforce and keep data in synch till new functionality is in place
c. Suggest MDM solution and link MDM to salesforce and SAP
d. Integrate SAP with Salesforce, SAP to legacy CRM but not legacy CRM to Salesforce
I picked c and d as the response
I think I would pick C, because it’ll be easier to disconnect the legacy CRM from the MDM later on, knowing SAP and Salesforce will be in sync
One more question , which I am not sure..
UC has new opty plan mgmnt system and salesforce is SOR for accounts, contacts oppty. But there is some good data in opty plan mgmt. system which does not exist in SFDC. How do u manage this?
A Take this up with stakeholders to chart out the process
B Overwrite data in salesforce
C Take the most recent data from the systems
D Since salesforce is SOR, ignore data from opportunity plan mgmt. system
I picked choice A. Not sure if that is correct
Thanks a lot @MACIEJ JÓŹWIAK
I have successfully completed Data Architect Designer Exam.Best Blog for overall topics in brief.
Glad that these articles help 😉 Congrats!
Thanks Maj I completed it today .. it was a very good experience ..purely the concepts wins ..